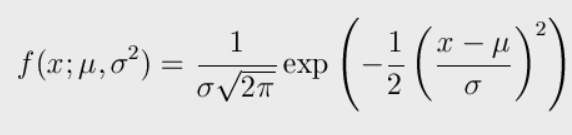
Verrà assegnato un punto in più (fino ad un massimo di 3) per
ogni errore o inesattezza che verrà trovata nel testo e/o nei relativi
esercizi di corredo al testo
Errata: p. 16 nella prima riga dell'esercizio la frase "creare nella colonna C" deve essere sostituita con "creare nella colonna D" (segnalato da Alice Bersani).
Errata: p. 17 riga -7 la frase "cliccare su un istogramma qualsiasi con il tasto destro del mouse e scegliere l'opzione "Formato asse"" deve essere sostituita con "cliccare su un istogramma qualsiasi con il tasto destro del mouse e scegliere l'opzione "Formato serie di dati"" . (segnalato da Roberto Bruno).
Il titolo della Figura 1.25 "Creazione di un grafico ad istogramma ed aggiunta delle etichette sull'asse delle categorie" deve essere sostituito con "Creazione di un grafico ad istogramma, aggiunta delle etichette sull'asse delle categorie e impostazione della scala dell'asse verticale".
Il titolo della Figura 1.26 "Impostazione della scala dell'asse verticale, dei colori delle barre e delle loro distanze" deve essere sostituito con "Impostazione dei colori delle barre e delle loro distanze".
Nella Figura 1.26(a) il puntatore del mouse dovrebbe essere sulla voce "Formato serie di dati" del menù contestuale.
Avvertenza per maggiore chiarezza il file contenente l'intervallo di pagine da 17 a 19 rettificato, è scaricabile qui.
Errata: p. 22 r. -4. La frase
"Ordinare le righe del dataset in ordine alfabetico prima per
nome e poi per cognome"
deve essere sostituito con "Ordinare le righe del dataset in ordine alfabetico
prima per cognome e poi per
nome" (segnalato da Ilaria Tarantino).
Errata: p. 29 r. -9. La frase
"Selezionare i valori della colonna K e copiarli nella colonna
N" deve essere sostituita con "Selezionare i valori
della colonna K e copiarli nella colonna L"
(segnalato da Maria Gison e Anna Martino).
Avvertenza p. 31 sulla funzione SUBTOTALE. Nella funzione SUBTOTALE vengono sempre ignorate le righe escluse nel risultato di un filtro, a prescindere dal valore specificato per l'argomento Num_funzione. Se per l'argomento Num_funzione vengono specificate le costanti da 1 a 11, la funzione SUBTOTALE include i valori delle righe nascoste tramite il comando Nascondi righe del sottomenu Nascondi e scopri del comando Formato disponibile nel gruppo Celle della scheda Home. Al contrario, se per l'argomento num_funzione vengono specificate le costanti da 101 a 111, la funzione SUBTOTALE esclude i valori delle righe nascoste tramite il comando Nascondi righe. Occorre, quindi, utilizzare le costanti da 101 a 111 se si desidera calcolare il subtotale solo dei numeri non nascosti di un elenco.
Errata: p. 36 nella prima riga della soluzione la frase "Si inseriscano nelle colonne I e J" deve essere sostituita con "Si inseriscano nelle colonne J e K" (segnalato da Ilaria Tarantino).
Errata: p. 37 nella seonda riga del testo dell'esercizio la frase "Inserire nella zona G7:H9 una formula che calcoli l'ammontare totale dei profitti realizzati dai 3 agenti nella zona G16:H21" deve essere sostituita con "Inserire nella zona G6:H8 una formula che calcoli per ciascun anno l'ammontare totale dei profitti realizzati dai 3 agenti nella zona G15:H20" (segnalato da Ilaria Tarantino).
Errata: p. 37 r. -2 sostituire la frase "nelle celle G7 e G16 e poi risolvere il resto per trascinamento" con "nelle celle G6 e G15 e poi risolvere il resto per trascinamento".
Errata: p. 40 quarta formula (5+1)/3 = 3 deve essere sostituito con (5+1)/2 =3 (segnalato da Daigoro Yamada).
Errata: nell'equazione (2.1) di p. 63 manca il simbolo di σ al denominatore. La formula corretta è la seguente:
Errata: p. 69 r. -5 la dicitura INV.NORM.ST.S deve essere sostituita con INV.NORM.S (segnalato da Ilaria Varotto).
Errata: p. 71 nella quint'ultima riga le formule di Excel
DISTRIB.NORM(-2.5;60;0.12;1) e DISTRIB.NORM(2;60;0.12;1)
devono essere sostituite con
DISTRIB.NORM(59.7;60;0.12;1) e DISTRIB.NORM(60.24;60;0.12;1)
(segnalato da Siro Descrovi)
Errata: p. 85 nella cella D9 della Figura 2.15 la frase "Quantile 0.0975" deve essere rimpiazzata con "Quantile 0.975" (segnalato da Alina Montagnano). Nella cella F5 la formula =INV.T.2T(0,05;D2) deve essere sostituita con =-INV.T.2T(0,05;D2).
Errata: p. 85 r. 7 la frase "con 1000 di libertà" deve essere sostituito con "con 1000 gradi di libertà". (segnalato da Maria Gison)
Errata: p. 85 nella cella D9 della Figura 2.15 la frase "Quantile 0.0975" deve essere rimpiazzata con "Quantile 0.975" (segnalato da Ivan D’Ambrosio)
Errata: p. 88 nello screenshot di Figura 2.17 nella cella C6 la formula =CONTA.NUMERI(A2:A13) deve essere rimpiazzata con =CONTA.NUMERI(A2:A13) -1 (segnalato da Alberto Madonini)
Errata: p. 90 nella prima formula a destra in alto per σ(P) manca il quadrato. Ossia σ2(P)=π(1-π)/n (segnalato da Siro Descrovi).
Errata: p. 91 r. -8 la frase "Infatti, riducendo γ, si riduce la probabilità 1- γ e di conseguenza si aumenta zγ/2" deve essere sostituita con "Infatti, riducendo γ, aumenta la probabilità 1- γ e di conseguenza aumenta zγ/2" (segnalato da Maria Gison).
Errata: p. 96 nella quart'ultima formula, manca la radice quadrata alla frazione 250/249. In altri termini, 26 × 250/249 deve essere sostituito con 26 × (250/249)0.5 (segnalato da Daigoro Yamada).
Errata: p. 99 nella terza riga la frase "...allora rifiuto H0 se z(\xmedio) ≤ -tγ allora non posso rifiutare H0", con "...allora rifiuto H0 se z(\xmedio) ≥ -tγ allora non posso rifiutare H0".
Avvertenza: p. 100. Nelle zone D10:D12 e G10:G12 della Figura 2.22 viene calcolato il livello di significatività ad una coda. In presenza di un'ipotesi alternativa bilaterale il p-value non è altro che il livello di significatività ad una coda moltiplicato per 2. Quindi, nelle zone C10:C11 e F10:F11 la dicitura "p-value del test" deve intendersi come "p-value del test diviso 2" dato che in questo caso l'ipotesi alternativa è bilaterale.
Avvertenza: Nella figura 2.22 il p-value del test per varianza non nota viene calcolato tramite la funzione DISTRIB.NORM.ST.N e non tramite la funzione DISTRIB.T.N per ribadire che Excel in presenza di varianza non nota utilizza erroneamente la v.c. Normale e non la v.c. T di Student.
Errata: p. 102-103.
p.102 r. -6, la frase "Esporre come sarebbero cambiate le conclusioni con γ =0.01" deve essere sostituita con "Esporre come sarebbero cambiate le conclusioni con γ =0.02".
p. 103 r. -3. la frase "Si perviene a tale conclusione sia utilizzando γ =0.05 oppure γ =0.01" deve essere sostituita con "Si perviene a tale conclusione sia utilizzando γ =0.05 oppure γ =0.02".
Avvertenza1: Chiaramente dato che il p-value a due code è pari a 0.0118 al livello di significatività dell'1% non possiamo rifiutare l'ipotesi nulla di uguaglianza dei carichi di rottura delle due corde.
Avvertenza2: nelle cella G26 il p-value deve intendersi come come calcolato ad una coda ossia assumendo un'ipotesi alternativa unilaterale sinistra.
Errata: p. 105 a partire dalla r. -12, nella regola di decisione per ipotesi nulla bilaterale occorre sostituire tγ con tγ/2 (segnalato da Siro Descrovi)
Errata: p. 107 nella cella H26 di Figura 2.26 la formula =INV.T(0,1;42) deve essere sostituita con =INV.T(0,1;51) (segnalato da Maria Gison).
Errata: p. 110 r. 11 la frase "utilizzando un livello di significatività γ=0.01", deve essere sostituito con "utilizzando un livello di significatività γ=0.05" (segnalato da Lorena Cottone).
Avvertenza: a p. 113 non si parla di regola di decisione unilaterale sinistra nell'ambito del test per la verifica di ipotesi sulle varianze di due popolazioni normali, dato che a numeratore come precisato nella riga -16 si usa sempre s12, ossia la più elevata tra le due varianze campionarie.
Errata: p. 113 r. 13 la formula H0: μ1=μ2=d0 deve essere sostituita con H0: σ12= σ22
Errata: p. 113 r -3 la frase "a livello di significatività γ=0.01", deve essere sostituita con "al livello di significatività γ=0.05".
Avvertenza: Excel assume che il modello di regressione non contenga l'intercetta (anche se voi come matrice X selezionate una zona che contiene la colonna di 1). Se il modello non contiene l'intercetta, Excel calcola la devianza di regressione come somma dei quadrati dei valori teorici. Stessa cosa accade per l'R quadro (v. p. 50 del testo). Di conseguenza, se volete avere dall'output di REGR.LIN il vero R2 e la vera devianza di regressione non dovete selezionare come zona X la colonna di 1 e dovete inserire nel terzo argomento di REGR.LIN la parola VERO, ossia: REGR.LIN(y_nota;X_nota, VERO, 1)